
3.8. 計算量
1. 計算量とは
計算量の理論は、アルゴリズムが問題を解決する際に必要な計算資源(時間やメモリなど)を定量的に評価するための理論です。例えば、1万件のデータを並べ替える際に、あるアルゴリズムAは1秒で終わるのに対し、アルゴリズムBは10分かかるといった違いを数学的に表現し、予測するための考え方です。特に、問題の規模が大きくなるにつれて、アルゴリズムの効率がどのように変化するかを理解するために重要です。情報処理技術者にとっては、計算量の概念を理解することは、アルゴリズムの選定や最適化において不可欠です。
2. 詳細説明
計算量理論は、主に以下の概念に基づいています:
- 時間計算量(Time Complexity): あるアルゴリズムが問題を解くのにかかる時間を表します。入力サイズ $n$ に対するアルゴリズムの実行時間を関数 $T(n)$ として表し、その増加率を解析します。
- 領域計算量(Space Complexity): あるアルゴリズムが必要とするメモリ量を表します。これも入力サイズ $n$ に依存します。
- オーダー記号(Big-O Notation): アルゴリズムの時間計算量や領域計算量の増加率を簡潔に表現するための記号です。例えば、アルゴリズムの実行時間が $T(n)=3n^2+2n+1$ である場合、入力サイズが大きくなると二次の項が支配的になるため、$O(n^2)$ と表します。これは「最悪の場合、処理時間は入力サイズの二乗に比例する」という意味です。
- P(Polynomial)問題: 多項式時間で解決可能な問題を指します。すなわち、時間計算量が入力サイズの多項式で表される問題です。例えば、整列問題(ソート)は $O(n \log n)$ のアルゴリズムで解けるため、P問題に属します。
- NP(Nondeterministic Polynomial)問題: 答えを推測して、その正しさを多項式時間で検証できる問題です。例えば、数独の解答が正しいかどうかは簡単に確認できますが、解答自体を見つけるのは難しいことがあります。すべてのP問題はNP問題の一部ですが、NP問題がP問題に属するかどうかは未解決の問題です。
- NP完全問題(NP-Complete): NP問題の中でも特に難しい問題群を指します。これらの問題のいずれか一つでも多項式時間で解けると証明されれば、すべてのNP問題がP問題になるとされています。巡回セールスマン問題(全ての都市を一度だけ訪問する最短経路を求める問題)などが典型例です。
主要なアルゴリズムの計算量
| アルゴリズム | 平均的な時間計算量 | 最悪の時間計算量 | 用途例 |
|---|---|---|---|
| バブルソート | $O(n^2)$ | $O(n^2)$ | 簡単な並べ替え |
| クイックソート | $O(n \log n)$ | $O(n^2)$ | 効率的な並べ替え |
| マージソート | $O(n \log n)$ | $O(n \log n)$ | 安定した並べ替え |
| 二分探索 | $O(\log n)$ | $O(\log n)$ | ソート済み配列での検索 |
| 線形探索 | $O(n)$ | $O(n)$ | 未ソート配列での検索 |
| ダイクストラ法 | $O(E \log V)$ | $O(E \log V)$ | 最短経路問題 |
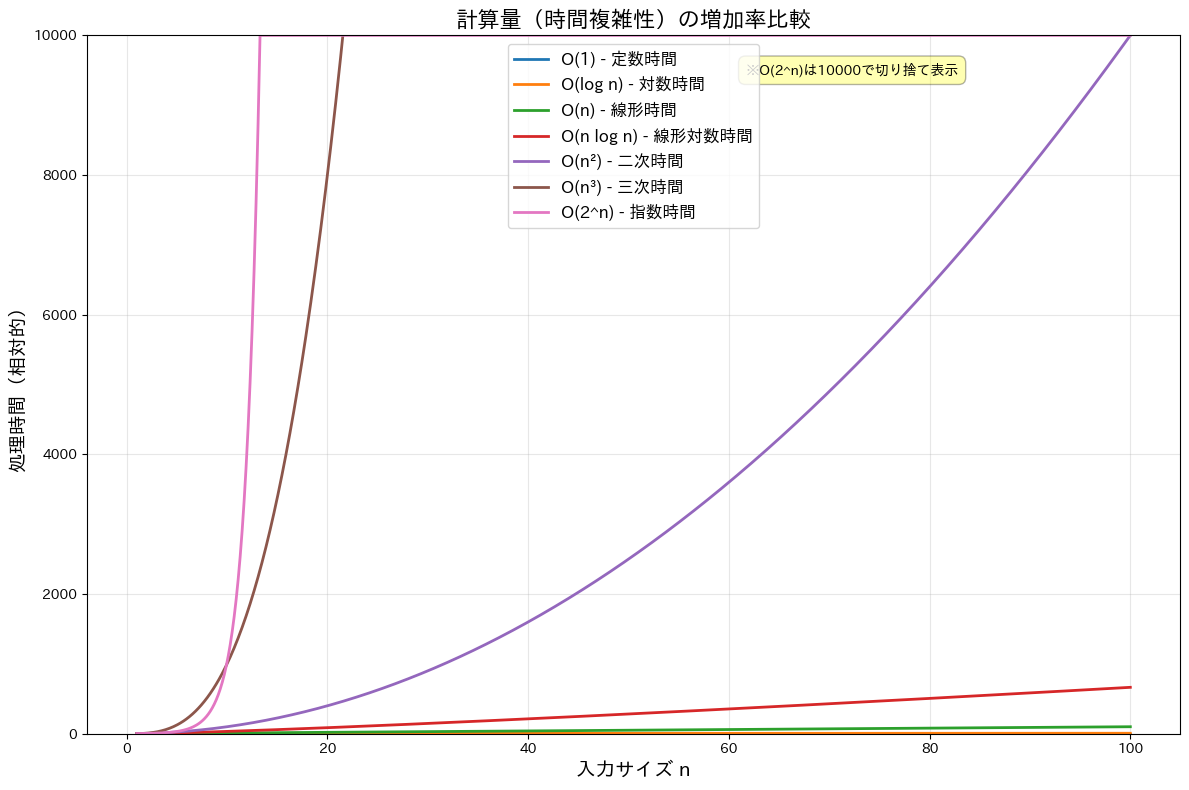
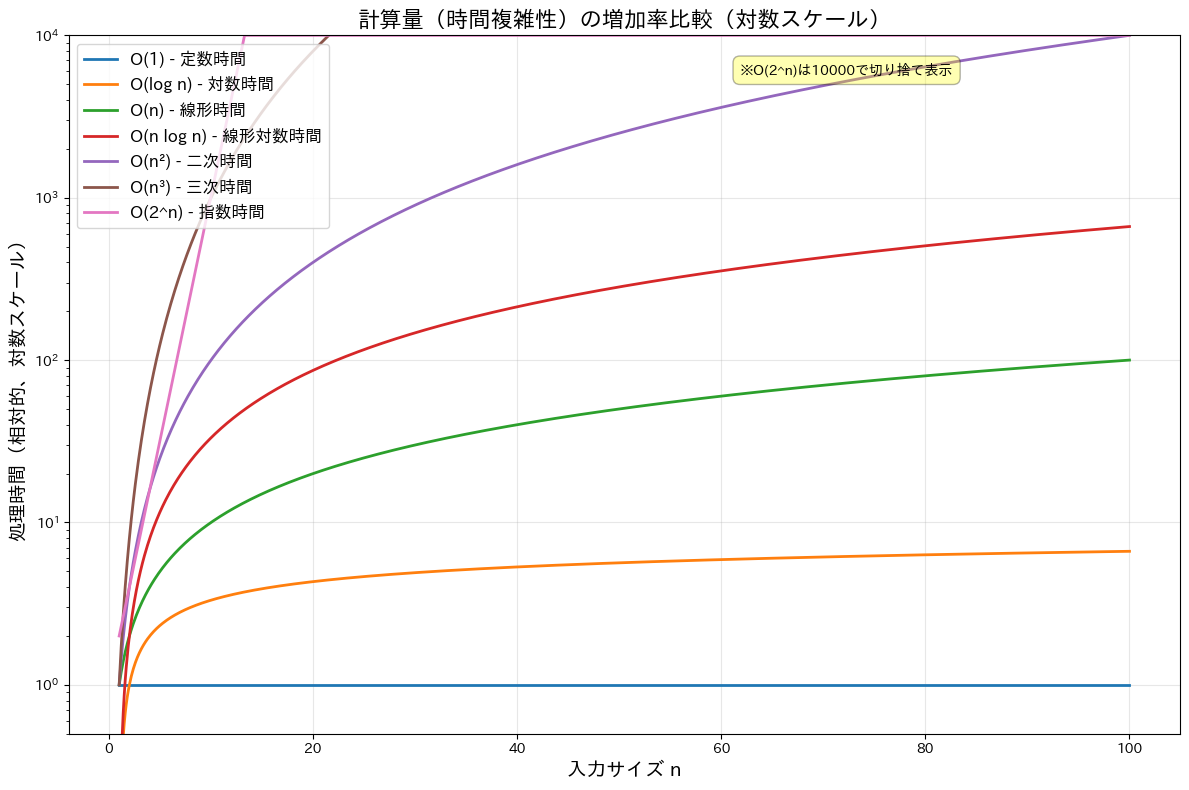
| 計算量 | n = 10 | n = 100 | n = 1,000 | n = 10,000 | n = 100,000 |
|---|---|---|---|---|---|
| O(1) 定数時間 | 0.01 ms | 0.01 ms | 0.01 ms | 0.01 ms | 0.01 ms |
| O(log n) 対数時間 | 0.03 ms | 0.07 ms | 0.10 ms | 0.13 ms | 0.17 ms |
| O(n) 線形時間 | 0.10 ms | 1.00 ms | 10.00 ms | 100.00 ms | 1.00 秒 |
| O(n log n) 線形対数時間 | 0.33 ms | 6.64 ms | 99.66 ms | 1.33 秒 | 16.61 秒 |
| O(n²) 二次時間 | 1.00 ms | 100.00 ms | 10.00 秒 | 16.67 分 | 27.78 時間 |
| O(n³) 三次時間 | 10.00 ms | 10.00 秒 | 2.78 時間 | 11.57 日 | 31.71 年 |
| O(2^n) 指数時間 | 10.24 ms | 4.02 × 10^13 年 | ∞ | ∞ | ∞ |
注意事項:
- 上記の時間は、1操作あたり0.01ミリ秒かかると仮定した理論的な計算結果です。
- 実際の実行時間はハードウェア、プログラミング言語、実装方法などによって大きく異なります。
- 「∞」と表示されている部分は、現実的な時間内に計算が終わらないことを示しています。
- 色分け:
速い
普通
遅い
非常に遅い
現実的でない
3. 応用例
計算量の理論は、実際のコンピュータ科学や産業界で多くの応用があります。例えば、以下のような状況で計算量の理論が活用されています:
- 暗号理論: 計算量の難しさを利用して、安全な暗号システムを構築しています。現代の暗号アルゴリズムの多くは、大きな数の素因数分解や離散対数問題などの計算量が大きい問題に依存しています(ただし厳密には素因数分解はNP完全問題ではないので注意が必要です)。
- 最適化問題: 生産計画や物流の最適化において、P問題やNP問題を解決するためのアルゴリズムが使われています。例えば、営業巡回問題(Traveling Salesman Problem)はNP完全問題の一例であり、多くの現実的な応用があります。配送ルートの最適化や工場での部品組立順序の最適化などに応用されています。
- データベースのクエリ最適化: データベースシステムでは、クエリの実行効率を向上させるために、アルゴリズムの計算量を最適化する必要があります。クエリプランの生成やインデックスの選定は、計算量理論に基づいた最適化が求められます。例えば、インデックスを適切に設定することで、検索の計算量を $O(n)$ から $O(\log n)$ に削減できる場合があります。
効率の違いを示す実際のコード例
以下は、同じ問題(配列内の特定の値を検索する)を解く2つの異なるアルゴリズムの例です:
線形探索($O(n)$):
def linear_search(arr, target):
for i in range(len(arr)):
if arr[i] == target:
return i # 見つかった位置を返す
return -1 # 見つからなかった二分探索($O(\log n)$)(ソート済み配列が前提):
def binary_search(arr, target): left, right = 0, len(arr) - 1
while left <= right:
mid = (left + right) // 2
if arr\[mid\] == target:
return mid # 見つかった位置を返す
elif arr\[mid\] < target:
left = mid + 1 # 右半分を探索
else:
right = mid - 1 # 左半分を探索
return -1 # 見つからなかったdef binary_search(arr, target):
left, right = 0, len(arr) - 1
while left <= right:
mid = (left + right) // 2
if arr[mid] == target:
return mid # 見つかった位置を返す
elif arr[mid] < target:
left = mid + 1 # 右半分を探索
else:
right = mid - 1 # 左半分を探索
return -1 # 見つからなかった入力サイズが100万のソート済み配列で最悪のケースを考えると:
- 線形探索: 最大で100万回の比較操作($O(10^6)$)
- 二分探索: 最大で約20回の比較操作($O(\log_2 10^6) \approx O(20)$)
この違いは、特に大規模なデータを扱う場合に非常に重要になります。
4. 練習問題
問題1: アルゴリズムAの時間計算量が $T(n)=5n^3+2n^2+n+7$ で表されるとします。このアルゴリズムのオーダー記号(Big-O Notation)は何ですか?
解答
$T(n)=5n^3+2n^2+n+7$ において、最高次の項は $5n^3$ です。したがって、このアルゴリズムの計算量は $O(n^3)$ です。これは入力サイズが大きくなるにつれて、処理時間が入力サイズの3乗に比例して増加することを意味します。
問題2: ある問題がNP完全問題であることが分かっています。この問題を解くためのアルゴリズムが多項式時間で見つかったと仮定します。この場合、PとNPの関係にどのような影響がありますか?
解答
もしNP完全問題が多項式時間で解けることが証明されれば、すべてのNP問題も多項式時間で解けることになります。つまり、P=NPとなり、計算量理論における最も重要な未解決問題の一つが解決することになります。これにより、現在は効率的に解けないとされている多くの問題が効率的に解けるようになる可能性があります。
問題3: 領域計算量が $O(n^2)$ であるアルゴリズムが存在します。このアルゴリズムが入力サイズ1000のデータを処理するとき、メモリ使用量のオーダーはどれくらいになりますか?
解答
領域計算量が $O(n^2)$ で入力サイズが1000の場合、メモリ使用量のオーダーは $1000^2 = 1,000,000$ になります。つまり、約100万単位のメモリが必要になる可能性があります。具体的な単位(バイト、KB、MBなど)は問題の性質により異なりますが、入力サイズの二乗に比例したメモリが必要になります。
5. まとめ
計算量理論は、アルゴリズムの効率を評価し、現実の問題を効果的に解決するための基盤を提供します。時間計算量と領域計算量の理解、オーダー記号の適用、P問題とNP問題の区別、そしてNP完全問題の重要性は、情報処理技術者にとって非常に重要です。
効率的なアルゴリズムを選択することで、同じ問題でも処理時間やメモリ使用量に劇的な違いが生まれます。特に大規模なデータを扱うモダンなシステム開発では、計算量を考慮したアルゴリズム選択が不可欠です。
実務では、常に「このアルゴリズムの計算量はどの程度か」「もっと効率の良い方法はないか」と考える習慣をつけることで、より高性能で信頼性の高いシステムを構築することができます。計算量の概念を理解し応用することは、ソフトウェアエンジニアとしての基本的なスキルの一つです。
6. 参考文献
問題解決のための「アルゴリズム×数学」が基礎からしっかり身につく本 (Amazonアソシエイトリンク)
「2.4 計算回数を見積もろう〜全探索と二分探索〜」が参考になります。
※この記事にはAmazonアソシエイトのリンクが含まれています。購入された場合、収益の一部を得ることがあります。